Lancement d’Ollama ollama launch
23 janvier 2026


Comprendre Ollama et OpenCode :
Étapes pour lancer un projet
Considérations
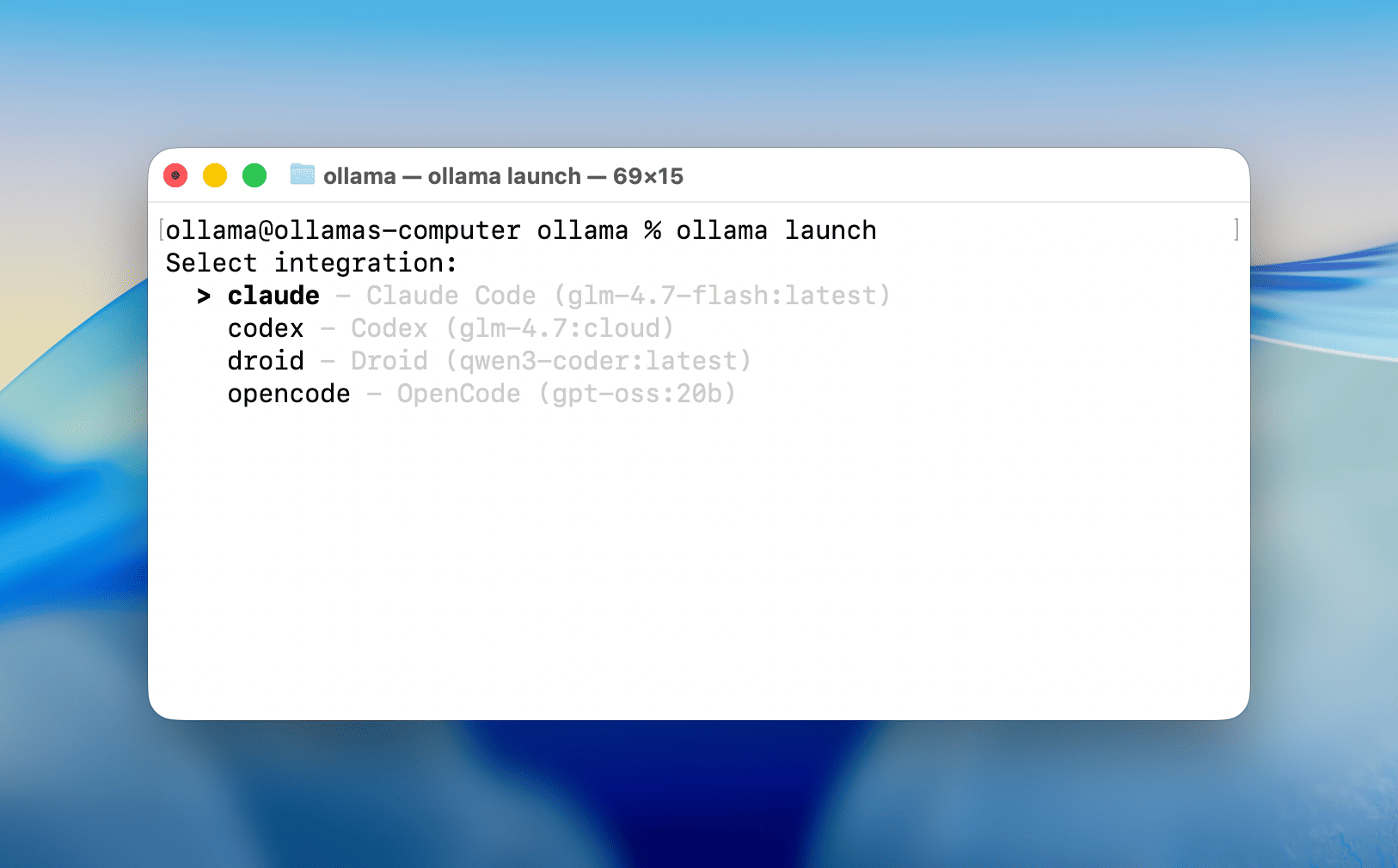
ollama launch est une nouvelle commande qui configure et exécute vos outils de codage préférés comme Claude Code, OpenCode et Codex avec des modèles locaux ou cloud. Aucune variable d’environnement ni fichier de configuration n’est nécessaire.
Commencez
Téléchargez Ollama v0.15+, puis ouvrez un terminal et exécutez :
# ~23 GB VRAM required with 64000 tokens context length
ollama pull glm-4.7-flash
# or use a cloud model (with full context length)
ollama pull glm-4.7:cloud
Configuration d’une commande
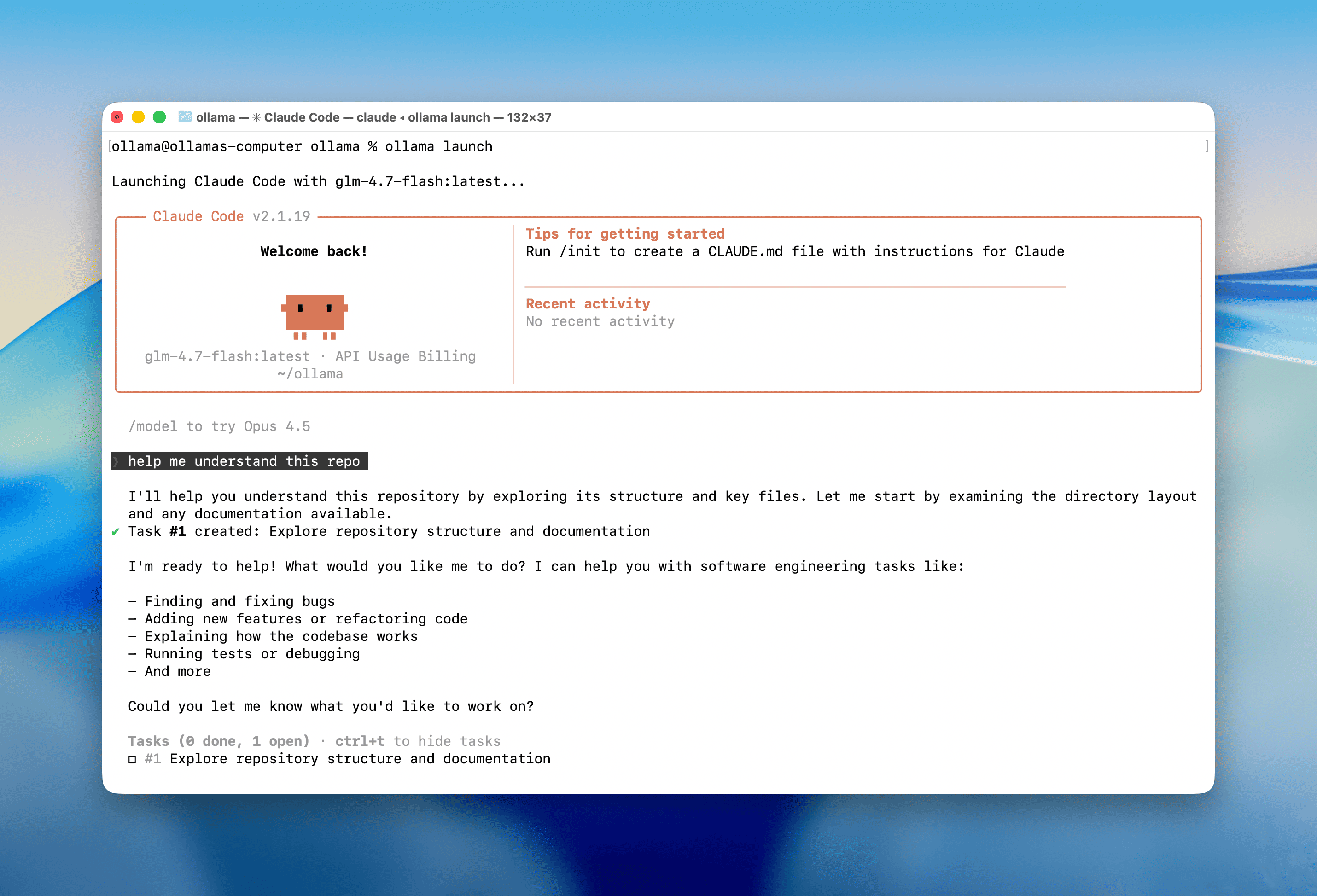
Code Claude :
ollama launch claude
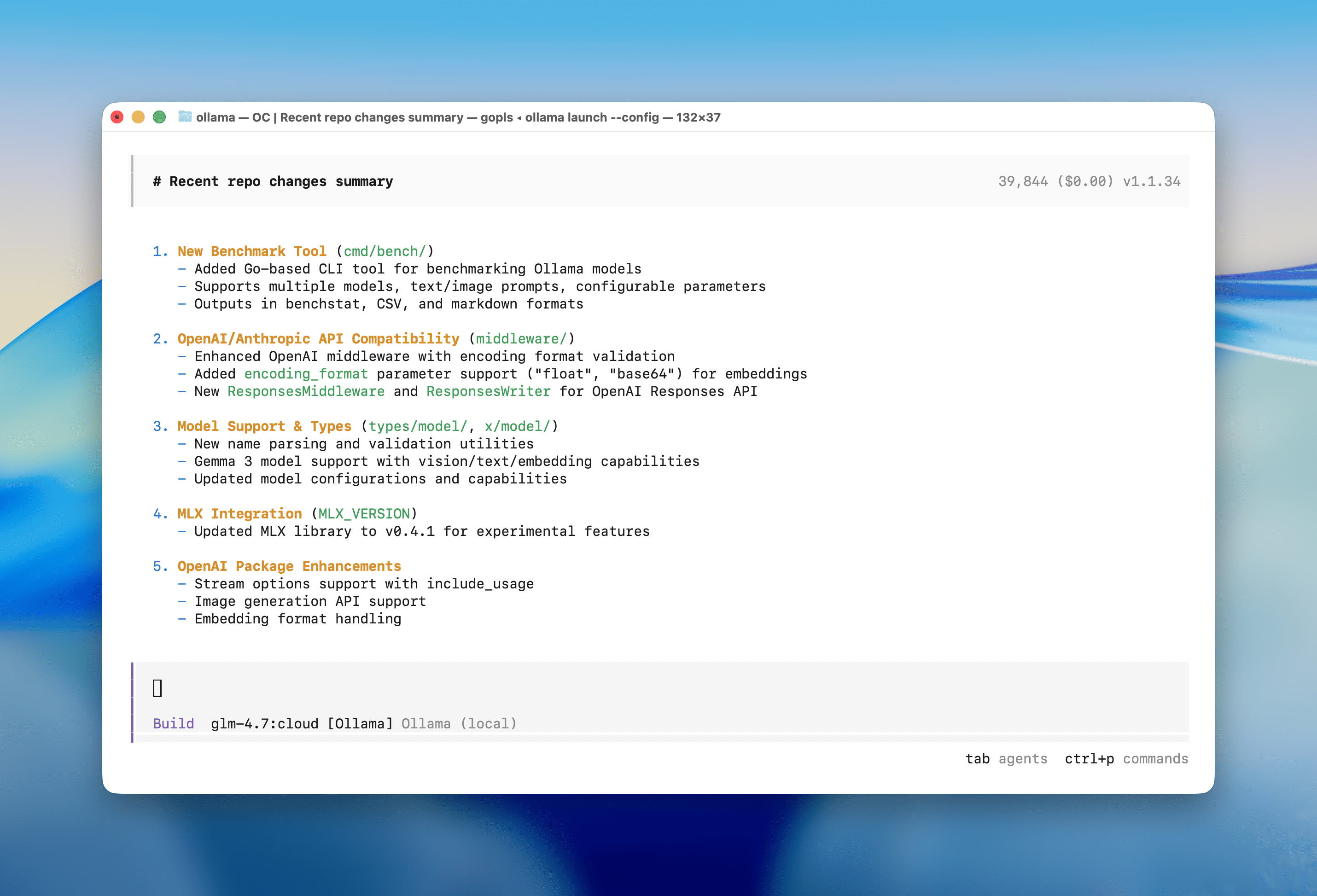
OpenCode :
ollama launch opencode
This will guide you to select models and launch your chosen integration. No environment variables or config files needed.
Supported integrations
- Claude Code
- OpenCode
- Codex
- Droid
Recommended models for coding
Note: Coding tools work best with a full context length. Update the context length in Ollama’s settings to at least 64000 tokens. See the context length documentation on how to make changes.
Local models:
glm-4.7-flashqwen3-codergpt-oss:20b
Cloud models:
glm-4.7:cloudminimax-m2.1:cloudgpt-oss:120b-cloudqwen3-coder:480b-cloud
Extended coding sessions
If you have trouble running these models locally, Ollama also offers a cloud service with hosted models that has full context length and generous limits even at the free tier.
With this update Ollama now offers more usage and an extended 5-hour coding session window. See ollama.com/pricing for details.
Configure only
To configure a tool without launching it immediately:
ollama launch opencode --configollama/ollama: Get up and running with OpenAI GLM-4.7, DeepSeek, gpt-oss, Qwen, Gemma and other models.https://github.com/ollama/ollama/blob/main/README.mdhttps://github.com/ollama 
Context length - Ollama https://docs.ollama.com/context-length
Pas possible avec PHI4

Mieux avec Mistral

Le service est :

■ We're currently experiencing high demand, which may cause temporary errors.
Mon dernier livre :
LA DICTATURE DE L’IA ET SA GOUVERNANCE. : Reprendre le contrôle : Guide pratique pour une souveraineté numérique européennede Pierre GIRAUDYCe livre diagnostique la dépendance critique de l'Europe aux infrastructures numériques américaines (GAFAM + NVIDIA) et chinoises (BATX), transformant la commodité technologique en vulnérabilité stratégique. Il y est estimé qu'entre 65% et 80% la probabilité de perturbations majeures des services cloud américains en Europe d'ici 2028 pourrait être effectives, rendant urgent le développement d'alternatives souveraines et Européennes.
Le livre combine analyse géopolitique rigoureuse et guides techniques pratiques, proposant une feuille de route en six chapitres : diagnostic de la colonisation numérique, évaluation des risques géopolitiques, panorama des alternatives européennes (GAIA-X, OVHcloud, Scaleway), maîtrise technique de l'IA locale via la stack Ubuntu + Ollama + Mistral/PHI4 (SLM), gouvernance collective (GINUM, AI Act), et plan d'action opérationnel (PRAN).
Voir un retour d'expérience concret (REX) démontrant qu'une infrastructure souveraine coûte 34% moins cher qu'une solution GAFAM sur 5 ans (économie de 225k€ annuels pour une PME de 100 employés), tout en éliminant les risques géopolitiques. Le livre inclut un thriller techno géopolitique fictif ("La Grande Déconnexion") illustrant un scénario de coupure des câbles transatlantiques et perte des GPS / horloges atomiques.
Destiné aux DSI, dirigeants d'entreprise, décideurs publics et citoyens éclairés, cet ouvrage démontre que la souveraineté numérique n'est ni utopie idéologique ni repli protectionniste, mais une condition opérationnelle de liberté, de sécurité et de prospérité à l'ère de l'IA.Certains de mes autres livres :
Pour en savoir plus sur moi, mes blogs :
https://www.ugaia.eu/ https://larselesrse.blogspot.com/
https://gouver2020.blogspot.com/
https://cluboffice2010.blogspot.com
Sur YouTube :
https://www.youtube.com/@EROLGIRAUDY
Mes 15 livres :
https://www.ugaia.eu/p/mes-livres.html
Dans| le Catalogue général de la BnF :
Users Group Artificial Intelligence Agentique (U.G.A.I.A.) mon blog : https://www.ugaia.eu
Mes réseaux sociaux : http://about.me/giraudyerol
L' AI pour la Généalogie de UGAIA
L’intelligence artificielle des service pour les généalogistes : https://uga-ia.blogspot.com/


Aucun commentaire:
Enregistrer un commentaire
Merci pour ce commentaire